
Pythonでconcurrent.futuresにより並列化(マルチスレッド化)を行いI/Oバウンドな処理を高速化する方法を説明する。
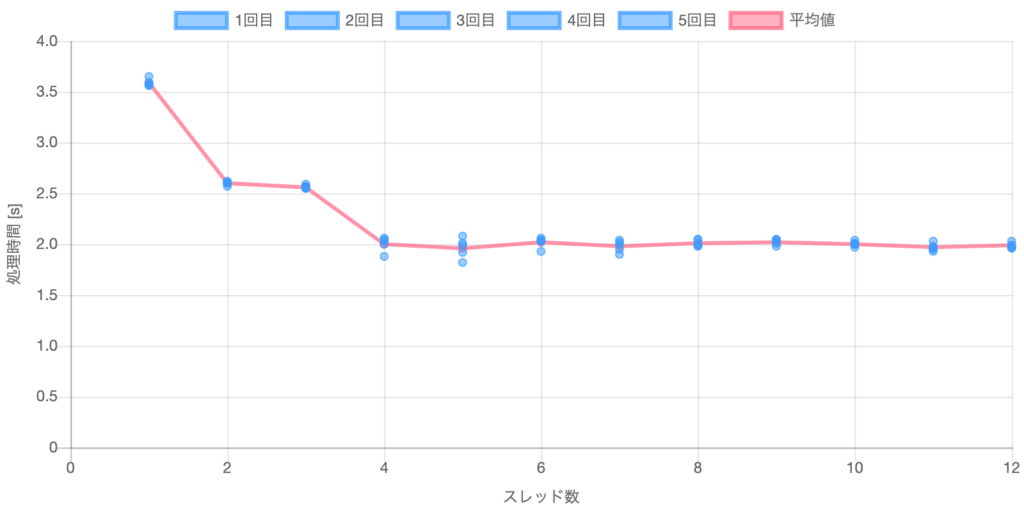
結果イメージ
CSVファイル(275MB)4個を読み込む時間をスレッド数を振って測定した。読み込み時間は1スレッドのときに対し2スレッドで70%、4スレッドで60%に低減した。
本記事の対象
本記事ではマルチスレッドでのI/Oバウンドな処理を対象とする。
| I/Oバウンドな処理 ※3 | CPUバウンドな処理 ※4 | |
| マルチスレッド ※1 | 本記事はここが対象 | |
| マルチプロセス ※2 |
※1 マルチスレッド
・順番に複数のコアで処理を行う。同時に複数のコアで処理はできないが、I/Oバウンドな処理であればI/O待ち時間が発生するのであるコアのI/O待ち時間を使って他のコアが処理をすることで高速化ができる。CPUバウンドな処理では高速化できない。
※2 マルチプロセス
・同時に複数のコアで処理を行う。I/Oバウンドな処理でもCPUバウンドな処理でも高速化できる。
・プロセス間メモリ共有できないので共有したい場合はプログラムする必要がある。
※3 I/Oバウンドな処理
– I/Oバウンドな処理とは処理速度がI/Oサブシステムの速度によって制限される処理。
(例)HDD/SSD/ネットワーク上のファイル読み書き
※4 CPUバウンドな処理
– CPUバウンドな処理とは処理速度がCPUの速度によって制限される処理。
(例)forループ、数値計算、圧縮/解凍、暗号化処理、画像変換処理
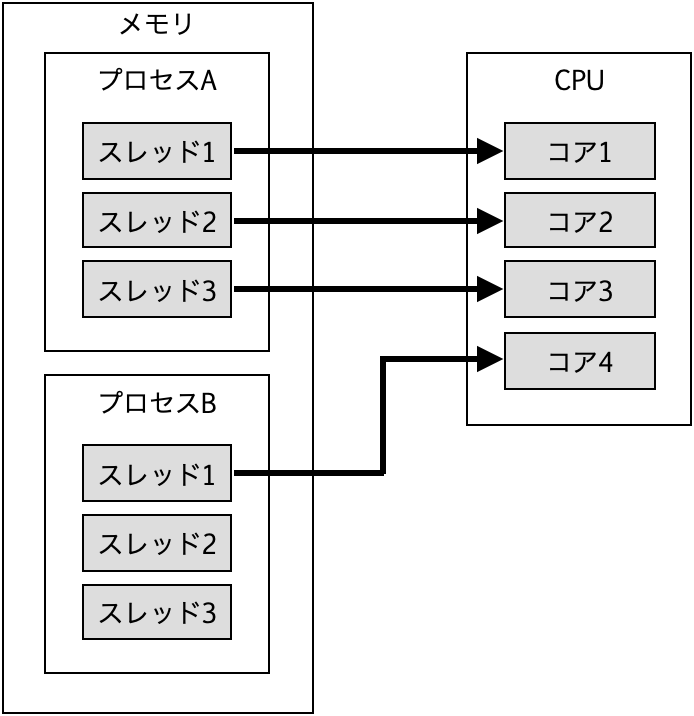
スレッドとCPUコアの関係
- スレッドは各CPUコアに対して命令を与えることができる。
- 1つのプロセス内のスレッドはプログラムの作りにより複数持つことが可能。
- 同一プロセス内のスレッドはメモリ空間を共有できる。
- CPUコアの数だけ同時に命令できる。
マルチスレッド化の方法
concurrent.futuresのThreadPoolExecutorを使う。下記に例を示す。ex_out1、ex_out2がマルチスレッド処理される。
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=スレッド数) as executor:
ex_out1 = executor.submit(マルチスレッド化させたい処理)
ex_out2 = executor.submit(マルチスレッド化させたい処理)
便利な書き方としてmapを使うこともできる。例えば複数のファイルを読み込む場合はイテレータに複数ファイルのリスト[file1, file2, ・・・]を入れる。後述の具体例ではこの方法を使う。
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=スレッド数) as executor:
ex_out = executor.map(マルチスレッド化させたい処理, イテレータ)具体例
マルチスレッドのスレッド数を振ってファイル読み込み速度を測定し、スレッド数を増やすほどファイル読み込み速度が速くなるか確認する。
条件
- スレッド数 : 1〜12
- CPU : 12コア
- 読み込むファイル数 : 4個
- 読み込むファイル : CSVファイル(275MB)
- ファイル読み込み方法 : pandasのread_csv()
- 測定回数 : 5回
処理イメージ
スレッド数1の場合は1スレッドで4ファイルを処理する。
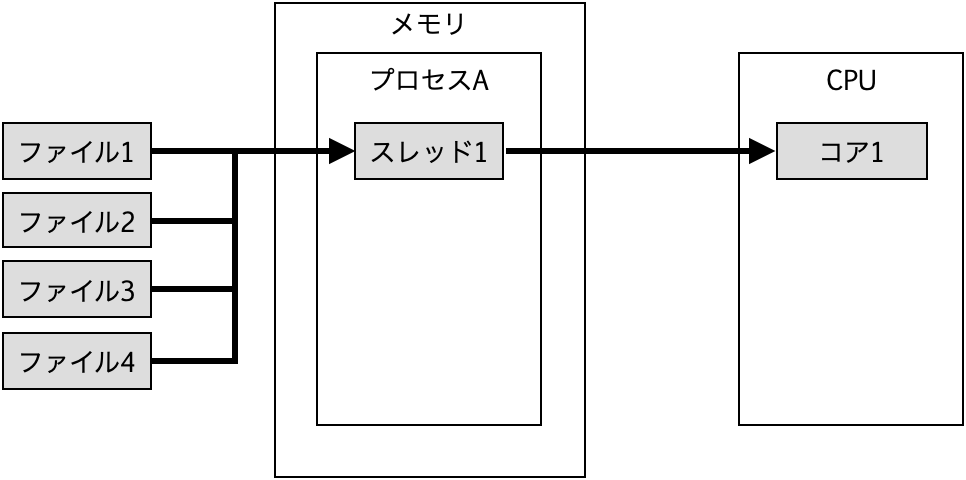
スレッド数2の場合は1スレッドあたり2ファイルを処理する。
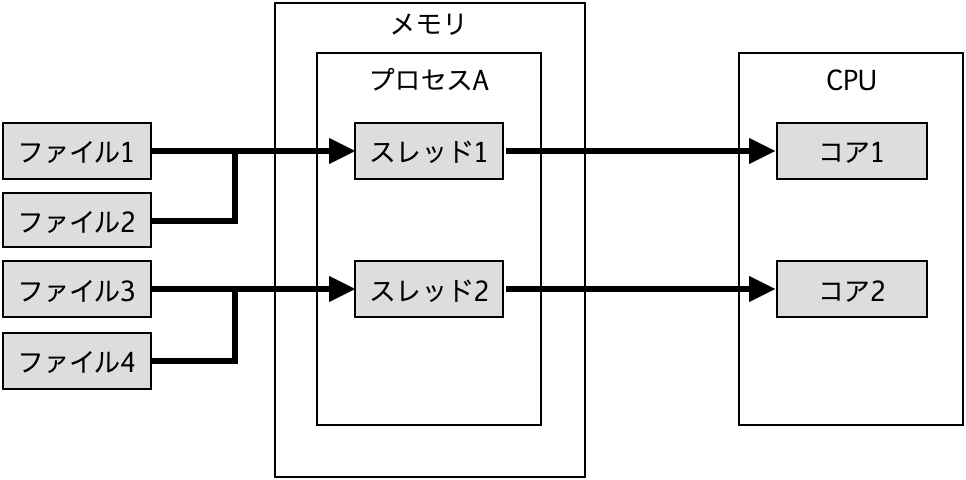
スレッド数4の場合は1スレッドあたり1ファイルを処理する。
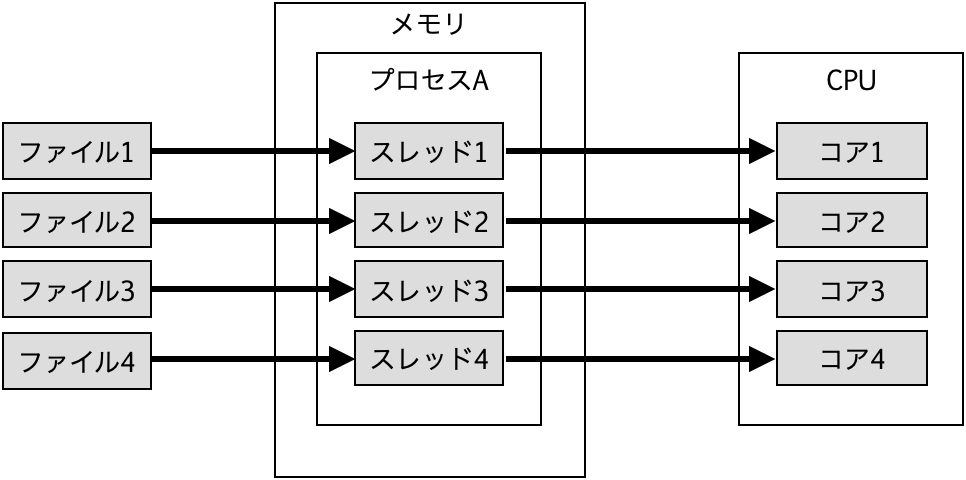
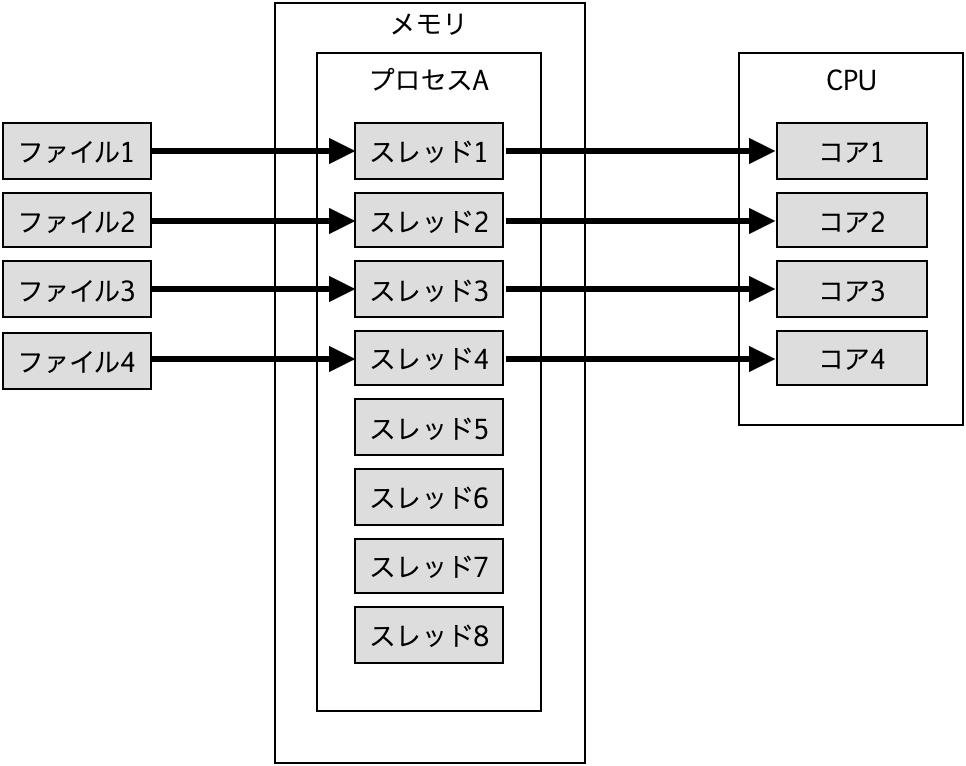
スレッド数5以上の場合はファイル数よりスレッド数の方が多くなる。
コード
このコードでスレッド数を1から12まで振る。
- concurrent.futuresからThreadPoolExecutorをインポートする。
- 読み込み対象の4つのCSVファイルをリストとして用意する。
- マルチスレッド処理するコードを記述する。
- I/Oバウンドな処理としてCSVファイルを読み込むコードを記述する。
- スレッド数を引数にマルチスレッド処理を行う。
- 処理時間を計算する。
#!/usr/bin/env python3
from concurrent.futures import ThreadPoolExecutor # 1
from time import time
import pandas as pd
ファイルリスト = ['/Users/yoshihiko/Desktop/yoshihiko1.csv',\ #2
'/Users/yoshihiko/Desktop/yoshihiko2.csv',\
'/Users/yoshihiko/Desktop/yoshihiko3.csv',\
'/Users/yoshihiko/Desktop/yoshihiko4.csv']
def マルチスレッド(スレッド数): # 3
with ThreadPoolExecutor(max_workers=スレッド数) as executor:
ex_out = executor.map(IOバウンドな処理, ファイルリスト)
def IOバウンドな処理(file_list): # 4
result = pd.read_csv(file_list)
return result
start = time()
マルチスレッド(スレッド数=1) # 5
end = time()
print(end - start) # 6結果
読み込み時間は1スレッドのときに対し2スレッドで70%、4スレッドで60%に低減した。処理時間はスレッド数1から2、3から4にかけて減少した。スレッド数2と3はほぼ変化が無かった。スレッド数4以降はほぼ変化が無かった。
| スレッド数 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均値 |
| 1 | 3.57 | 3.57 | 3.59 | 3.56 | 3.65 | 3.59 |
| 2 | 2.62 | 2.61 | 2.57 | 2.60 | 2.60 | 2.60 |
| 3 | 2.55 | 2.56 | 2.55 | 2.57 | 2.59 | 2.56 |
| 4 | 2.04 | 1.88 | 2.04 | 2.00 | 2.06 | 2.00 |
| 5 | 2.01 | 2.08 | 1.82 | 1.92 | 1.99 | 1.96 |
| 6 | 1.93 | 2.06 | 2.03 | 2.04 | 2.03 | 2.02 |
| 7 | 2.00 | 1.90 | 2.04 | 2.02 | 1.95 | 1.98 |
| 8 | 1.99 | 2.04 | 2.05 | 1.98 | 1.99 | 2.01 |
| 9 | 2.01 | 2.05 | 2.04 | 2.04 | 1.98 | 2.02 |
| 10 | 2.01 | 2.04 | 2.00 | 1.97 | 2.00 | 2.00 |
| 11 | 1.95 | 2.03 | 1.98 | 1.93 | 1.96 | 1.97 |
| 12 | 1.99 | 2.03 | 1.96 | 1.97 | 1.97 | 1.96 |
単位 : 秒
考察
- ファイル数が4個と偶数なのでスレッド数2と3ではほぼ変化が無かったと推定。
- ファイル数が4個なのでスレッド数4以降はほぼ変化が無かったと推定。
まとめ
マルチスレッド化によりファイル読み込み速度が高速化できることが確認できた。


コメント